


The real challenge with dynamically scaling a media delivery platform is managing high concurrency when conferences or stream viewership peaks and eventually subsides.
Let us consider, for example, the number of concurrent users ranging between 100-1,000 across 10-100 conferences. It would be a good idea to autoscale the number of active media server instances based on usage to save a significant amount of cost and resources.
Jitsi’s architecture allows for dynamic scaling in real-time. Our previous blog provides the rationale behind using Jitsi Videobridge [JVB] as the media server. In addition to being powerful and optimized, JVBs are built to scale, which make them more dynamic for media transport.
Architecture:
The below figure shows a simplified diagram explaining the scaling architecture for running multiple conferences.
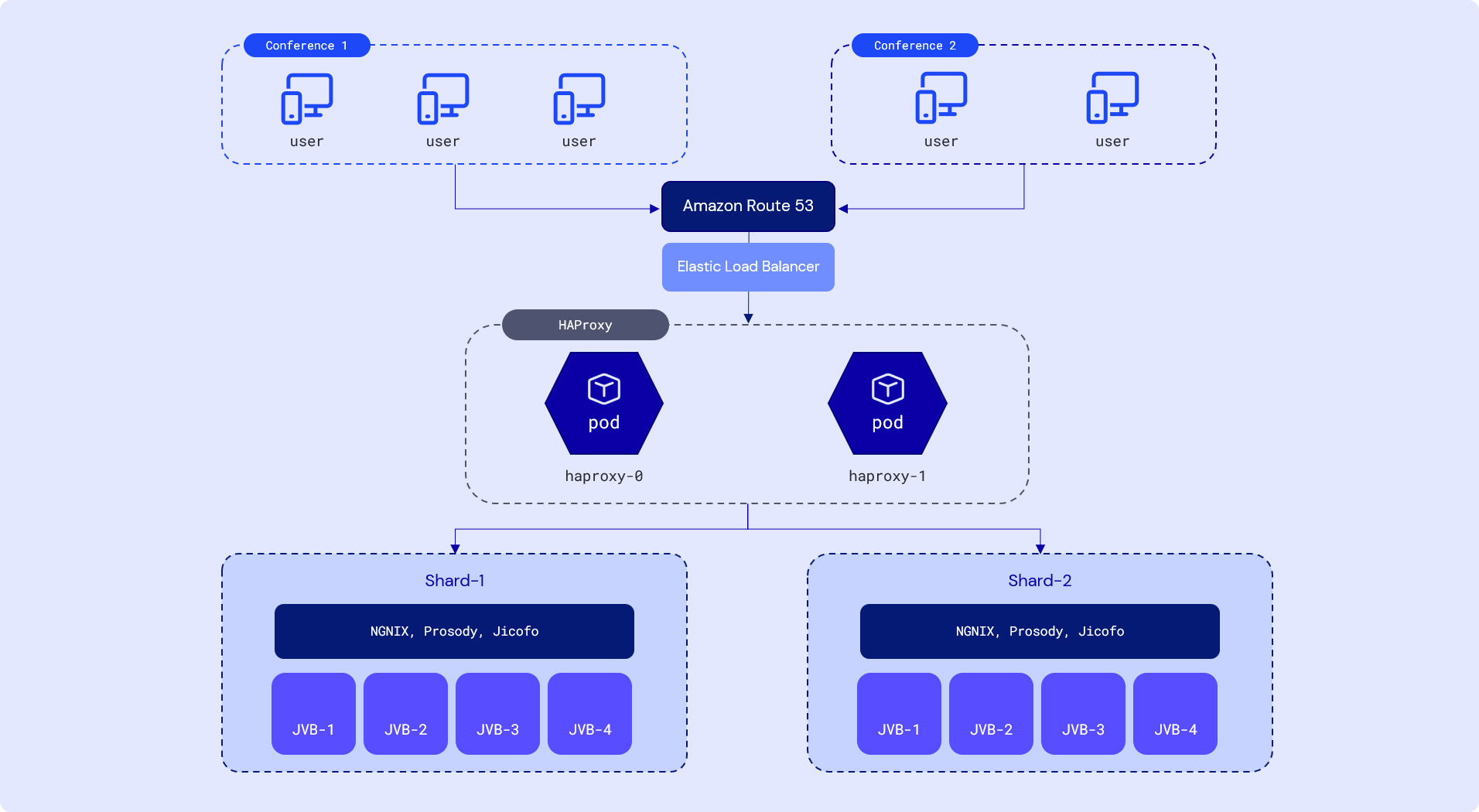
Amazon Route 53
Route 53 is a highly available and scalable DNS web service which routes end users to internet applications by translating human readable names, e.g., meet.sariska.io. The route policy used in our case is the geolocation routing policy, which routes traffic based on the location of your users.
Application Load Balancer
The Elastic Load Balancer automatically distributes incoming application traffic across multiple targets and virtual appliances in one or more Availability Zones (AZs).
HAProxy
The incoming connections need to be load-balanced between the shards. Additionally, new participants that want to join a running conference need to be routed to the correct shard.
A service running multiple instances of HA-Proxy, a popular open source software TCP/HTTP load balancer and proxying solution, is used for this purpose. New requests are load-balanced using the round-robin algorithm for fair load distribution. HAProxy uses DNS Service Discovery to find existing shards.
In the event there is an existing conference a user needs to join, HAProxy uses sticky tables to route all traffic for an existing conference to the correct shard. Sticky tables work similar to sticky sessions. In our example, HAProxy will store the mapping of a conference room URI to a specific shard in a dedicated key-value store that is shared with the other HAProxy instances.
Shard
The use of the term "shard" describes the composition that contains single containers for jicofo, prosody and multiple containers of JVB running in parallel.
A single shard component will contain the following services inside:
- NGNIX Server
- Jicofo manages media sessions between each of the participants in a conference and the videobridge. It uses the XMPP protocol for service discovery of all videobriges, chooses a videobridge and distributes the load if multiple video bridges are used. When connecting to a client, Jicofo will point to a videobridge that the client should connect to. It holds information about which conferences run on which videobridges.
- Prosody is an XMPP communication server that is used by Jitsi to create multi-user conferences.
- Jitsi Videobridge
Shard Arrangement:
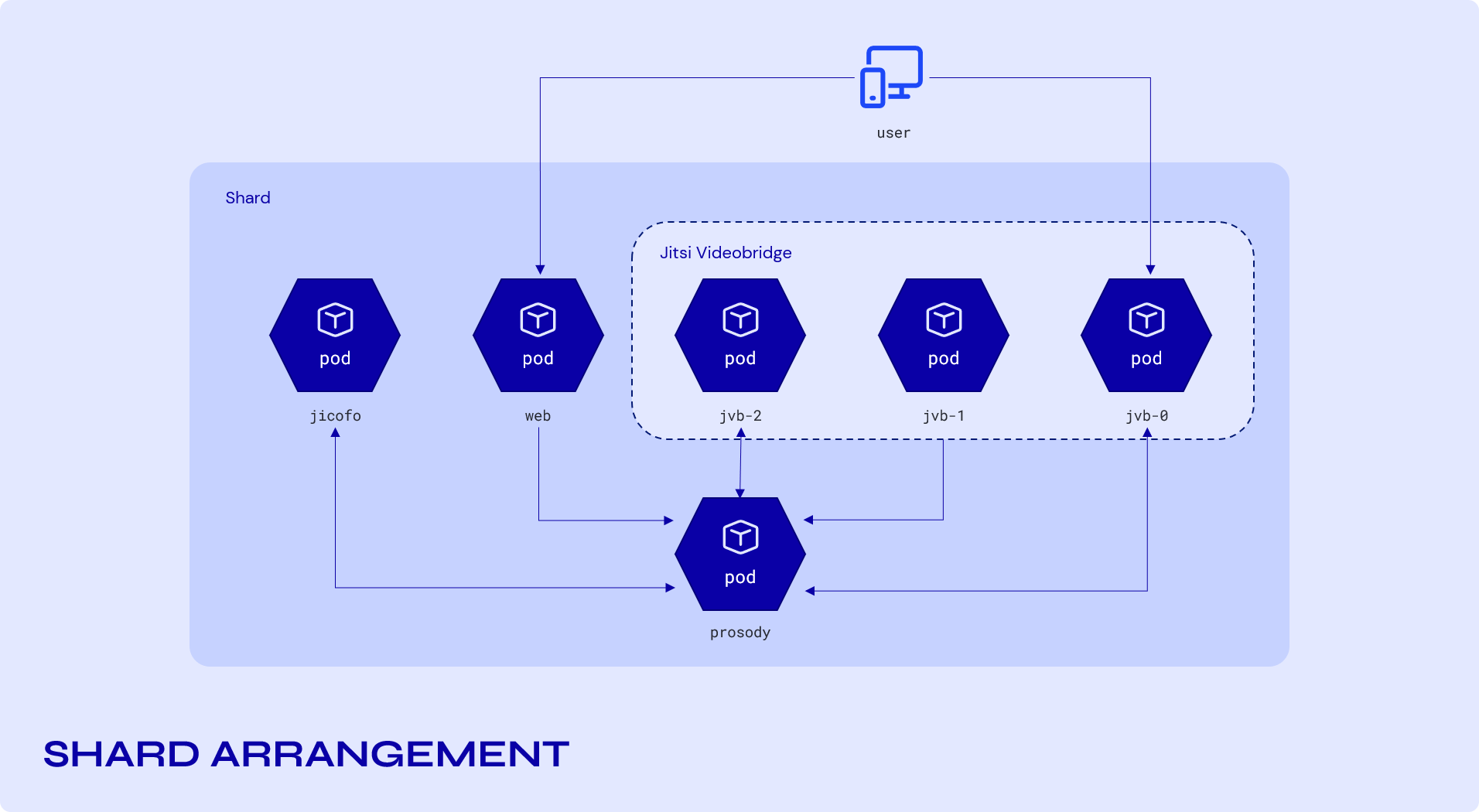
In the setup shown above for a shard, the videobridges can be scaled up and down depending on the current load (number of video conferences and participants). The videobridge is typically the component with the highest load and therefore the main part that needs to be scaled.
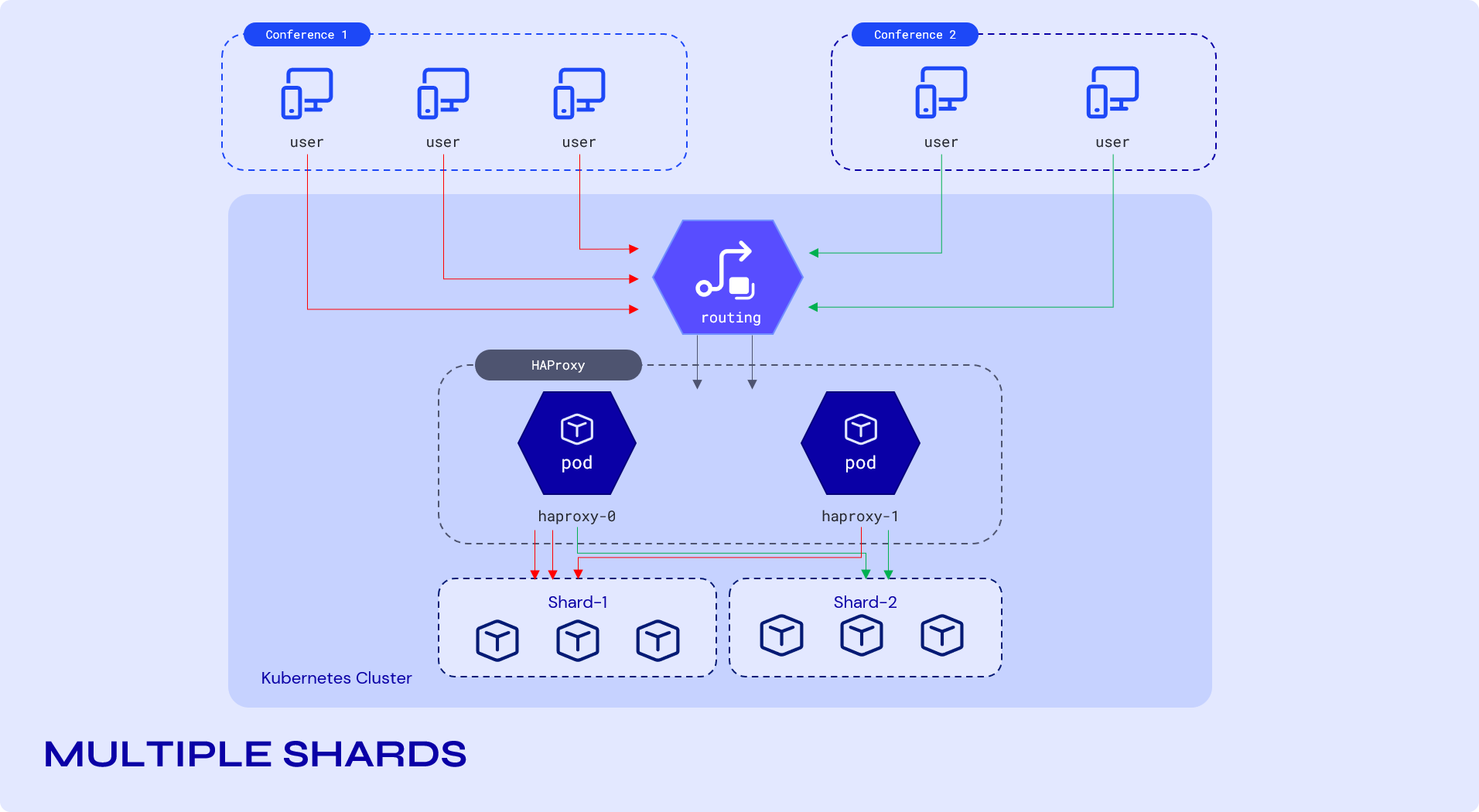
Nevertheless, the single containers (web, jicofo, prosody) are also prone to running out of resources. This can be solved by scaling to multiple shards as shown above. These shards are load balanced by HAProxy.
Implementation
Signaling Layer:
In a JVB-based conference, all signaling goes through a separate server-side application, which is mentioned above as Jicofo. When a user starts a conference, it is routed through the HAProxy to its correct shard, where Jicofo is responsible for managing media sessions between each of the participants and the videobridge. The signaling layer’s job thus consists of establishing a connection between users and assigning videobridges accordingly.
Once the user is assigned to a videobridge, the video streaming happens directly between the user and the videobridge. Therefore, the videobridges need to be open to the internet. This happens with a service of type NodePort for each videobridge (on a different port).
A horizontal pod autoscaler governs the number of running video bridges based on the average value of the network traffic transmitted to and from the pods. It is also patched in the overlays to meet the requirements in the corresponding environments.
Bridge-to-Bridge Communication:
Once the connection has been established using the signaling layers, the bridges take over. The connection between two bridges is only used for audio/video and data channel messages coming from clients, and no signaling takes place. This makes the task of cascading videobridges (OCTO Protocol) easy to implement.
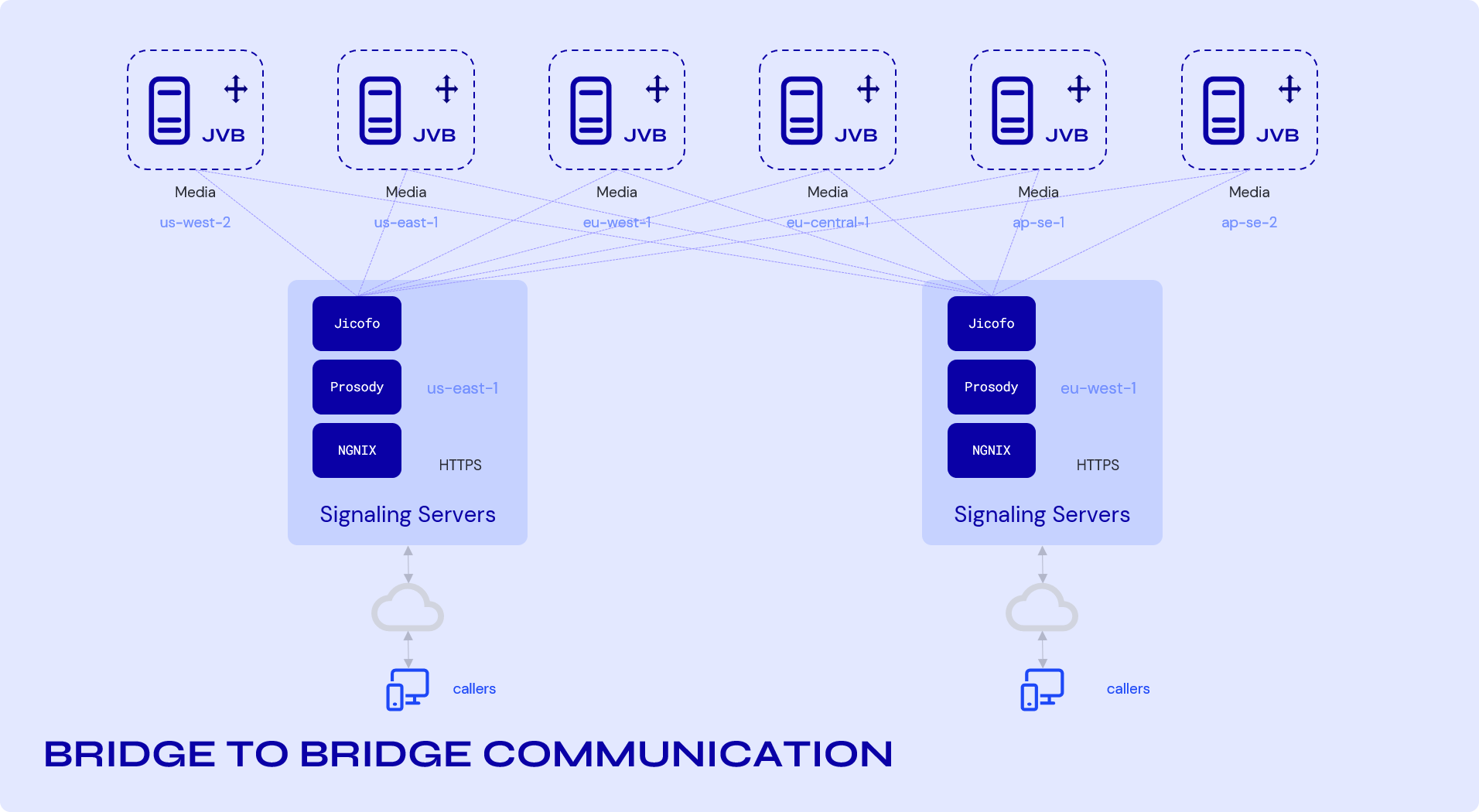
OCTO Protocol
A single videobridge for a single conference works well until the number of users in the conference is not too large. Also, if the users are in geographically farther locations, the issue of latency arises. The Octo Protocol routes video streams between videobridge servers, essentially forming a cascade of forwarding servers.
Octo removes the limit for a large number of participants in one conference due to the distributed client connections to multiple videobridges. On the other hand, Octo results in lower end-to-end media delays for geographically distributed participants.
Scaling Streaming Servers
Let’s now move on to the second part of this blog, and talk about scaling the live streaming infrastructure.
Sariska addresses the challenges of concurrent streaming and latency by using a media server called SRS (Simple Realtime Server), which is a simple, high-efficiency, and real-time video server supporting RTMP/WebRTC/HLS/DASH/HTTP-FLV/SRT protocols.
SRS is used as a real-time media delivery server on top of our video conferencing architecture. This enables you to push your streams through multiple outlets in a single click with simulcast enabled live streaming and reach your audience across every platform.
Architecture
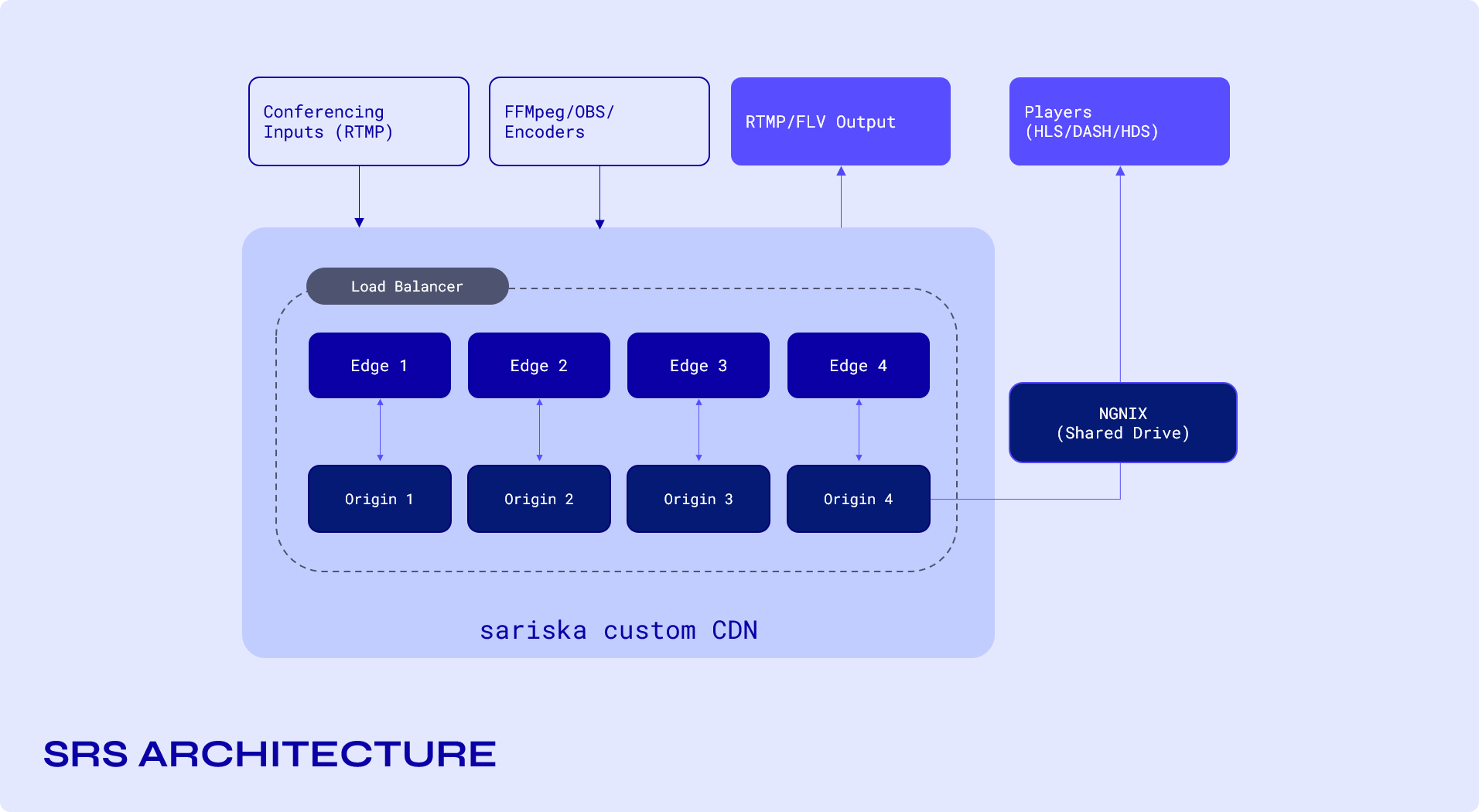
Loading balancing streaming servers
For a server, load is the consequence of increasing resource consumption, at the time of handling more requests from clients. These resources can be CPU resources, Network Bandwidth or Memory (Disk or RAMx).
Most of the time, live streaming is network or I/O intensive, hence network becomes the most critical bottleneck.
Special Challenges for Streaming Server:
In addition to general resource consumption, there are some additional factors that affect load or load balancing in a streaming server:
- Long connection: Live streaming requires long connection, some of which can last for more than a day or two. Therefore, the load of the streaming media servers has the characteristics of long connection, which complicates load balancing streaming servers.
- Stateful: The number of interactions between media server and its clients do not just end with starting or ending a stream. There are some interim states, which makes the load balancing server unable to directly pass the request to a new server when there is a problem with the service.
- Correlation: In live streaming, the push stream can affect all the playback.
Edge vs Origin Servers
SRS uses the concept of edge and origin servers, the tasks of efficiently transcoding, remuxing, demuxing and delivery are distributed between these two servers.
Edge server is responsible for ingestion of stream to the origin server and efficient delivery of the said streams to players on request at high concurrency numbers.
Origin server on the other hand, are responsible for transcoding and/or remuxing the ingested streams.
Load Balancing Edge and Origin Servers
Edge Cluster:
Edge is essentially a
Frontend Server and solves the following problems:- To expand the capability of live streaming, edge servers are scaled horizontally.
- In order to solve for nearby services, edge servers are generally deployed in the cities closest to the target users of the streaming service.
- The load balancing of Edge itself relies on a scheduling system, such as DNS or HTTP-DNS.
Origin Cluster:
SRS Origin Cluster, different from the Edge Cluster, is mainly to expand the origin server’s capability:
- If there are massive streams, such as 10k streams, then a single origin server cannot handle it, and we need multiple origin servers to form a cluster.
- To solve the single-point problem of the origin server, we could switch to other regions when a problem occurs in any region if there are multi-region deployments.
- For stream discovery, the Origin Cluster will access an HTTP address to query stream, which is configured as another origin server by default, and could also be configured as a specialised service.
- RTMP 302 redirection, if the stream is not on the current origin server, it will be redirected to another origin server.
From the aspect of load balancing, the origin cluster fits the job as a scheduler.
- Use
Round Robinwhen the Edge returns to the origin server
- Query the specialised service of which origin server should be used
- Actively disconnect the stream when the load of the origin server is too high and force the client to re-push to achieve load balance
Efficiency Comparison:
The following table below gives a comparison of SRS with other servers when compared on per server basis.
Feature
SRS
NGINX
CRTMPD
AMS
WOWZA
Concurrency
7.5k
3k
2k
2k
3k
MultipleProcess
Stable
Stable
X
X
X
RTMP Latency
0.1
3s
3s
3s
3s
HLS Latency
10s
30s
X
30s
30s
Conclusion:
In this post, we covered how Sariska scales the architecture of our media server and how, using SRS, we can also empower real-time media delivery efficiently for high-concurrent viewership.
Scaling the audio/video conferencing architecture is made easier with the usage of Jisti Videobridges due to the separation of the signaling layer from the transport layer. Adding SRS on top of our video conferencing allows us to stream to millions of existing conference concurrently.
If you are looking to work with a team that strives to simplify complex layers technologies, do get in touch with us directly on twitter/linkedin @sariskaio.

